
Abstract
Increased usage of social media, particularly during election seasons, has intensified political division and hate speech. In line with this, a study was conducted to build a model that would automatically detect hate speech and provide understanding on patterns of hate speech in a local political context.
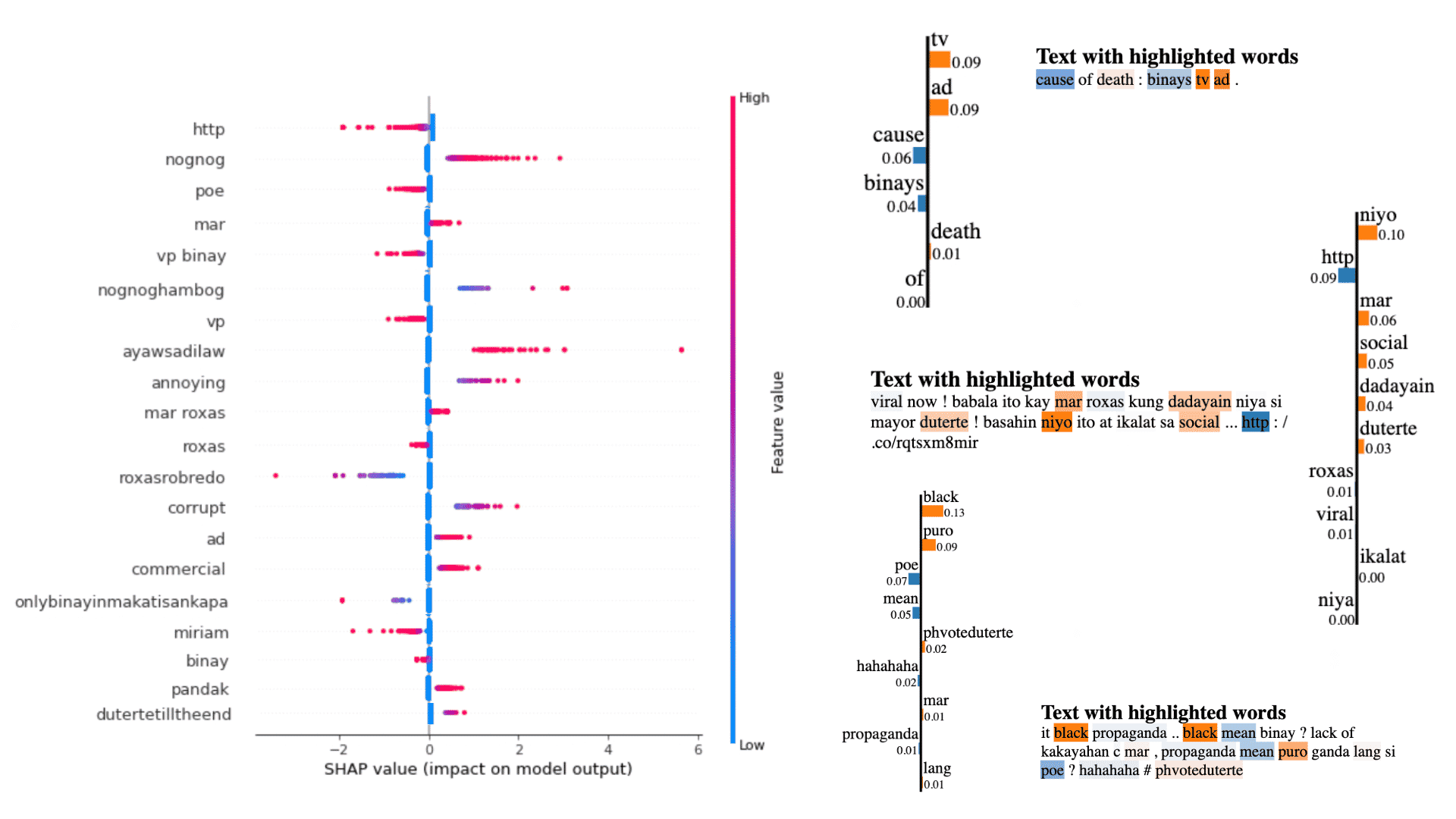
The study utilized a dataset of tweets scraped during the 2016 Philippine electoral campaign that are labeled as hate and non-hate speech. Data was cleaned and processed using various NLP methods such as TF-IDF, then various machine learning classifier models were built including linear, tree-based, and multilayer perceptron models. Hyperparameter tuning was performed to arrive at the best models based on accuracy and runtime. The best model was then used to test another dataset made up of recently scraped and manually labeled tweets about the 2022 elections. Finally, SHAP was employed to understand the factors that contribute to hate speech on a global scale, and another interpretability method, LIME, was used to interpret the results on a local level.
Among the models built, Logistic Regression had among the best accuracies, with the shortest runtime. This same model trained on 2016 data was then used to classify tweets from the present election campaign season. Global and local interpretability were then used to derive real-world insights from the results.
Some of the key findings are that netizens naturally use certain keywords and nicknames when bashing candidates, with their sentiments varying depending on the name of choice. Also, a common behavior found on specific candidates’ supporters is that their hate tweets are also mostly directed to the other supporters rather than the opposing candidates themselves. Political ads can also make or break a candidate’s campaign as negatively accepted ads may cause a huge volume of hate tweets online. Meanwhile, links to websites or external sources on a person’s tweet, depending on the election season, can be used to legitimately inform or be weaponized for hate-mongering online.
To further improve the applicability of the model on future studies, it is recommended to use a larger 2022 election related dataset either for testing or retraining the model. Labeling techniques such as semi-supervised learning can also be deployed to ease the difficulty of manual labeling.