
Executive Summary
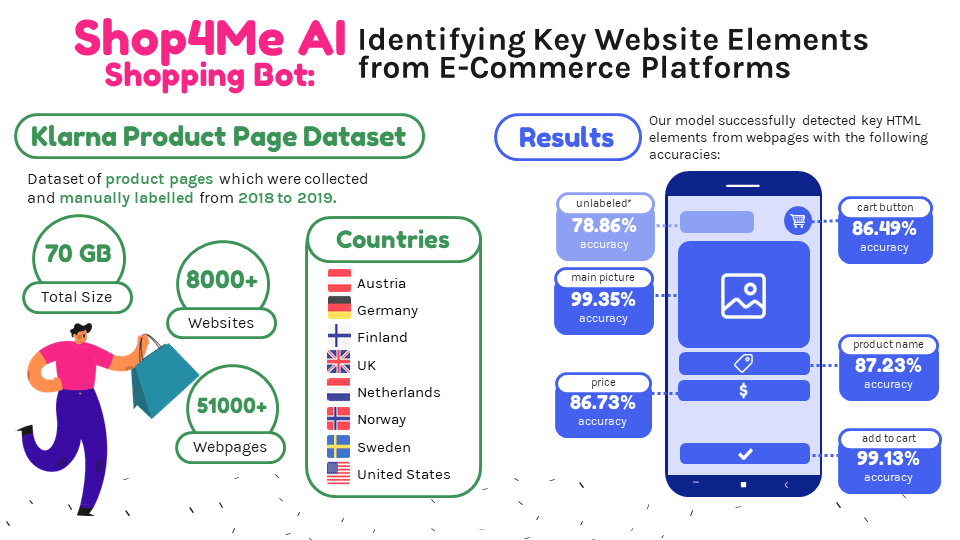
Despite the multi-trillion dollar worth of the global e-commerce industry, very limited work was done on webpage representation learning, content extraction, and node classification — ultimately limiting the progress in performing web-based automation. The key barrier behind the lack of progress in this space is the lack of rich datasets for Web perception. As such, the Klarna Product Page dataset was developed to explore the unique problem of machines navigating the Web.
With this fresh and unique dataset, the goal of this study is to identify key Hypertext Markup Language (HTML) elements from variously designed e-commerce websites as the first step toward furthering web perception techniques and applications related to automated shopping bots and other information retrieval techniques.
Using a mix of Term Frequency–Inverse Document Frequency (TFIDF) and One vs. Rest classification, we were able to achieve satisfactory results with accuracy scores of 78.86% for the unlabeled nodes and at least 86% for the labeled nodes: cart button, main picture, price, product name, and add to cart. Labeled nodes with the highest predictive accuracy are the main picture and add-to-cart with over 99% accuracy. This is relatively comparable with the various neural networks explored in the Klarna Product Page Dataset: A Realistic Benchmark for Web Representation Learning (2021).
This study also created a prototype for the Shop4Me app that showcases one of the many use cases of our model once operationalized. Given a few keywords and some filters for a product, the app will scan the best deals satisfying the search parameters. Each item on the results page is then accompanied by the information from the Main Title, Price, and Main Picture buttons, along with the web page link itself.