
Abstract
As the importance of digesting large quantities of information grows, we set our sights on developing a model that extracts and summarizes topics from raw documents. However, current natural language processing (NLP) systems focus exclusively on either topic modeling or text summarization, with nothing that extracts themes and generates a summary for each. How can we extract topics from a document’s tokens while simultaneously generating a summary based on the sentence segments corresponding to the recovered topics?
In an attempt to spark progress in this sub-field of NLP, the team designed BERT-2EN1, a pipeline that explicitly combines topic extraction and document summarization. It takes inspiration from BERTopic’s architecture for topic extraction and applies cosine similarity-based extractive summarization for each generated topic. In BERT-2EN1’s topic extraction phase, the team made small and deliberate changes at each stage of BERTopic’s architecture, which ultimately made the pipeline flexible for single or multiple documents, and for structured or free-flowing discussion transcripts.
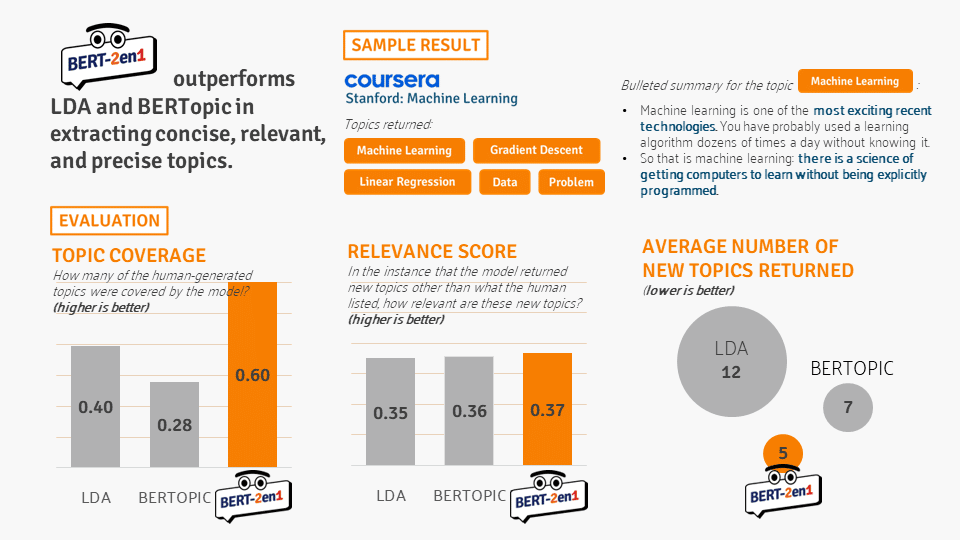
Our corpus consists of data science-related transcripts of heavily-structured lecture videos from Coursera, semi-structured lecture videos from Youtube, and minimally-structured talks from TED Talk. When BERT-2EN1’s performance was evaluated on three different metrics, we discovered that it returned topics that are concise (based on the number of topics returned), relevant (based on the percentage of overlap with human-generated topics), and precise (based on relevance of new topics returned). In terms of Topic Coverage, BERT-2EN1 extracted as much as 60% of the topics that humans recognized — significantly outperforming both Latent Dirichlet Allocation (LDA) and BERTopic. As some topics can be missed by humans themselves, we also evaluated if the extra topics returned by the model are relevant using the Relevance Score, to which BERT-2EN1 scored similarly with the other algorithms. However, despite similar Relevance Scores, our model was still superior in terms of returning a more condensed set of topics, with only five topics returned on average for each scanned document.