
Abstract
The United Nations has declared 2019 as the International Year of Indigenous Languages (IYIL). This is to raise alarm of how 40% of the world’s estimated 6,700 languages are now in the brink of disappearing, majority of them are ancient scripts that belong to indigenous communities. In the Philippines, Baybayin is just one of the many indigenous scripts that almost got lost in translation until it has recently gained resurgence of interest from various political, cultural, and educational organizations. Realizing the significance of this issue, the proponents of this project developed an image-processing machine learning model that could classify the 17 basic Baybayin alphabet.
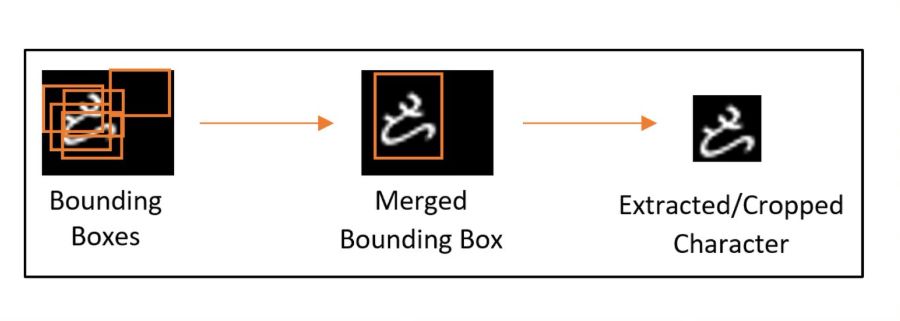
Usually, websites that offer Baybayin translation features accept English letters as input then return their Baybayin counterpart as output. This model does the reverse and takes in images written by hand. Due to the limited availability of data on the subject, handwritten samples were collected through crowdsourcing. The dataset was later scanned and converted into more than 1,000 images of individual Baybayin letters. Each image was fed into the model, which was then assigned an array of unique binary digits that served as the identity code of a specific character.
Currently, the model could correctly classify a Baybayin character almost 84% of the time, but this performance could be improved with more data. If further developed, the algorithm could be trained to recognize the more complex variations of the ancient script. It could as well be integrated to mobile tutorial apps that allow users to practice writing in Baybayin.